|
自20世纪90年代后期以来,机器翻译的方法和技术从传统的基于规则的机器翻译(RHAT)扩展到了诸如基于实例的机器翻译(EHMD)、基于模版的机器翻译(MT)、基于知识的机器翻译(KHAT)、统计机器翻译(SIT)、混合式机器翻译(HMD),机器翻译所依据的语言学理论则从以句法描述为特征的短语结构语法,发展到以语义描述为特征的格语法、依存语法、配价语法,再到以知识描述为特征的翻译系统以及本体论(Ontclogy)。机器翻译在走过了漫长的发 展历程后,其局限性仍然比较明显。究其原 因,是由于单一的机器翻译方法难以适应不同领域的需求所造成的。
目前常用的多引擎机器翻译系统中,各个翻译引擎各自独立地对输入的文本进行翻译,并将翻译的结果放到一个统一的数据结构中,最后由一个译文选择模块来选择出最好的译文组合。
Frederking提出了一种典型的并行多引擎机器翻译的方法。该方法基本思想描述如下:
多个的翻译引擎同时对输入的句子进行翻译,不仅仅对整个句子进行翻译,而且对句子的任何一个片断也可以给出相应的译 文,同时对这些译文片断给出一个评分。
各个翻译引擎共享一个类似线图的数据结构,根据其源文片断所处的位置,将这些译文片断放在这个公共的线图结构之中。
对各个引擎给出的片断的评分进行一致化处理,使之具有可比较性。
采用一个动态规划算法(称为Chart Walk算法)选择一组刚好能覆盖整个源文输入句子,同时又具有最高总分的译文片断,作为最后输出的译文。

系统结构如图1所示:
Hogan[2]通过一个简单的实验,证明这种方法确实可以得到比任何一种单一的方法都更高的准确率。
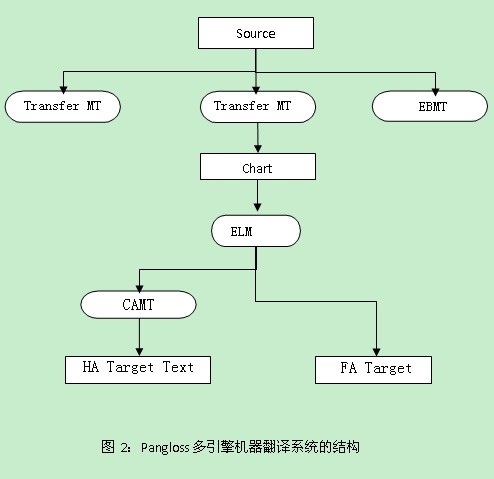
美国卡内基梅隆大学等单位研制的一个著名多引擎的西班牙―英语的机器翻译系统PANGLOSS系统就是采用的这种结构[3]。该系统总共包括三个翻译引擎:一个基于转换的翻译引擎、一个基于知识(中间语言)的翻译引擎和一个基于实例的翻译引擎。其系统结构如图2所示:
在很多多引擎的机器翻译系统中,并不是采用完全独立的多个翻译引擎对源文进行翻译,而是在机器翻译的不同阶段采用不同的算法,例如,在句法阶段采用基于规则的方法,在转换阶段采用基于实例的方法,而在生成阶段采用基于统计的方法。我们把这一种结构称为串行的多引擎机器翻译结构。在这种情况下,每个引擎实际上是翻译系统的一个部件,并不独立完成翻译任务。
还有很多系统采用的是一种混合的结构,并行中有串行(并行的多个翻译引擎之一又采用串行的多引擎结构),串行中有并行(串行的多个翻译部件之一又采用多个组件并行),形成一种复杂的体系结构。
并行的机器翻译结构各个翻译引擎的颗粒度非常大,引擎之间的结合非常松散,一个翻译引擎无法引用另一个翻译引擎的中间结果,这严重限制了整个系统性能的提高。因此,采用这种方法的系统实际上比较少见,大多数多引擎的机器翻译系统实际上都是采用后两种结构。
不过,并行的多引擎机器翻译方法有一个突出的优点也是另外两种方法所不具备的,就是其易扩充性。在这种结构下,各个翻译引擎的程序接口完全相同,添加和删除新的翻译引擎变得非常简单,这使得程序的扩充变得非常容易。
而在串行和混合的多引擎机器翻译结构中,各个翻译引擎(部件)由于实现的功能不尽相同,各个翻译引擎之间存在复杂的通讯关系,翻译引擎无法采用统一的程序接口,这使得程序的扩充变得非常困难。
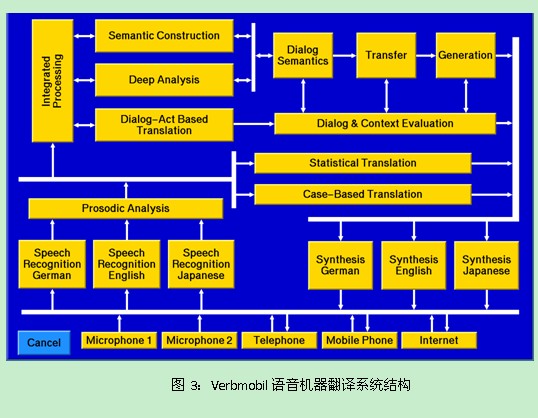
由德国教育与研究部(BMBF)资助开发的Verbmobil语音机器翻译系统就是一个典型的混合结构的多引擎机器翻译系统[6]。该系统规模非常庞大,整个系统的研制为期8年(1993-2000),涉及三种语言(德语、英语、日语)的双向翻译。世界三大洲的31个研究机构、369名科学家和919名学生(硕士生、博士生和博士后)参与了这个项目的研究。系统采用的技术也非常庞杂,语音处理领域和自然语言处理领域中常见各种技术都在这个系统中有所反映。整个系统由69个互相交互的模块构成。其中用到的自然语言处理技术包括:组块分析、概率LR分析、HPSG分析、对话行为(Dialog Act)分析、基于统计的翻译、基于子串(substring)的翻译、基于模板的翻译、基于模板的转换、语义分析、上下文相关歧义的消解、基于规划的话语生成,等等。
为了解决翻译引擎之间通讯的问题,Verbmobil系统采用一种多黑板结构用于模块之间的数据交互,模块之间不能直接通信。黑板结构还有利于各个模块之间的并行执行。总共采用了198个黑板结构用于69个不同模块之间的通讯。一种叫做VIT(Verbmobil Interface Terms)的数据结构在中心黑板的深层处理中用作深层的语义表示形式。该系统的整体结构如图3所示。
可以看到,由于黑板的设定是比较随意的,整个系统的复杂程度依然很高,模块的划分还不是非常清晰,系统的可扩充性也不是很好。
|




