|
Multi-engine MT
Since the late 1990’s, the methods and techniques of machine translation extended from traditional rule-based machine translation (RHAT) to example-based machine translation (EHMD), template-based machine translation (MT), knowledge-based machine Translation (KHAT), statistical machine translation (SIT), and hybrid machine translation (HMD). Machine translation is based on linguistic theory which develops from phrase structure grammar characterized by syntactic description, to case grammar, dependency grammar and valence grammar characterized by semantic description and then to translation system characterized by knowledge description and the ontology. After a long course of development of machine translation, its limitations are still obvious. The reason is because it is difficult for single MT method to adapt to the needs of different areas.
In the frequently used multi-engine MT system, each translation engine independently translates the input text, and puts the translated results into a unified data structure, and finally a translation selecting module chooses the best translation combination.
Frederking presents a typical parallel multi-engine MT method. The basic idea of the method described as follows:
Many translation engines translate the input sentences at the same time, not only translate the whole sentence but give the corresponding translations to any segment, and give a score to these translation segments.
Translation engines share a line chart similar data structure, according to the location of the source text fragments, and put these translation fragments in the public line chart structure.
Consistency processing of scores each engine gives to the fragments, so that they are comparable.
Using a dynamic programming algorithm (referred to as Chart Walk algorithm) to select a set just to cover the entire source text input sentences, while having the translation fragments with the highest total score as the final output translation.

System structure shown in Figure 1: Through a simple experiment, Hogan [2] using this method proved that higher accuracy can indeed be gained than any single method.
A famous multi-engine Spanish-English MT system PANGLOSS system, which was developed by Carnegie Mellon University and other institutions, used this structure [3]. The system consists of three translation engines: a transfer-based translation engine, a knowledge-based (intermediate language) translation engine and an example-based translation engine. The system structure shown in Figure 2:
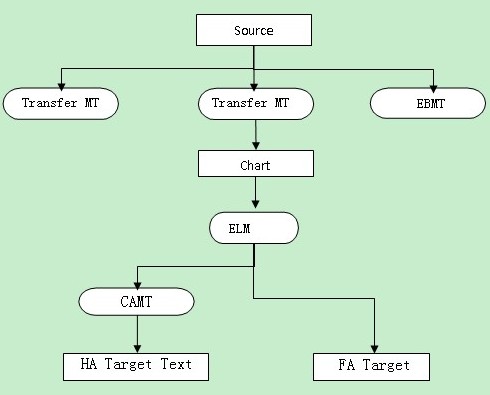
In many multi-engine MT systems, they don’t adopt a number of completely independent translation engines to translate the source text, and use different algorithms at different stages of MT. For example, adopt rule-based approach in the syntactic phase, adopt case-based approach in transition phrase and adopt statistics-based approach in the generation phrase. This structure is known as serial multi-engine MT structure.
There are many systems using a hybrid structure, parallel in serial (one of the parallel translation engines adopts serial multi-engine structure), and serial in parallel (one of the serial multiple translation parts adopts multiple components parallel) to form a complex architecture.
The granularity of each translation engine of parallel machine translation structure is large; the integration between the engines is very loose. A translation engine can not refer to the intermediate result of another translation engine, which severely limits the performance improvement of the overall system. Therefore, it is rare to see a system using this method, and most multi-engine MT systems are actually using the latter two structures.
However, the parallel multi-engine MT method has a prominent advantage which the other two methods don’t have, and it is the easy expandability. In this structure, the program interface of each translation engine is exactly the same, and adding and deleting new translation engine becomes very simple, which makes it very easy to expand the program.
In serial and mixed multi-engine MT structures, because the realized functions of each translation engine (component) vary, there is a complicated communication relationship between each translation engine. Translation engine can not adopt a uniform program interface, which makes expansion of the program becomes very difficult.
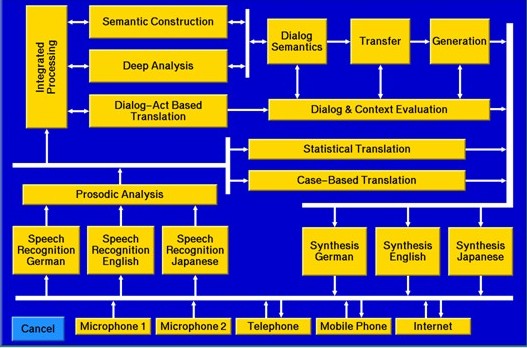
Verbmobil speech machine translation system funded by Germany’s Federal Ministry of Research and Technology (BMBF) is a multi-engine MT system [6] of a typical hybrid structure. The system has a large scale, and the developing period of the entire system is 8 years (1993-2000), involving two-way translation of three languages (German, English, Japanese). 31research institutions, 369 scientists and 919 students (master students doctoral students and postdocs) on three continents, participated in the study of this project. The technologies the system uses is also very complex, common technologies used in voice processing and natural language processing fields are reflected in the system. The system consists of 69 modules that interact with each other. Among which using natural language processing techniques include: chunk analysis, probability LR analysis, HPSG analysis, dialog act analysis, statistics-based translation, substring-based translation, template-based translation, template-based conversion, semantic analysis, resolution of context-sensitive ambiguity, plan-based discourse generation, and so on.
In order to solve the communication problem between translation engines, Verbmobil system uses a multi-blackboard architecture for data exchange between modules, and modules can not communicate directly. Blackboard structure is also beneficial to the parallel execution among various modules. A total of 198 blackboard structures are used in the communication between 69 different modules. A data structure called VIT (Verbmobil Interface Terms) in the deep processing of center blackboard is used as semantic representation. The overall structure of the system is shown in Figure 3.
It is can be seen that because the setting of blackboard is casual, the complexity of the whole system is still high, the module division is not very clear and the scalability of the system is not very good.
|




